博客字数统计以及 find 命令学习
字数统计的命令:
bash
find . -type f -name '*.md' -exec sed 's/!\[.*\](.*)//g; s/\[.*\](.*)//g' {} \; | wc -m运行结果: 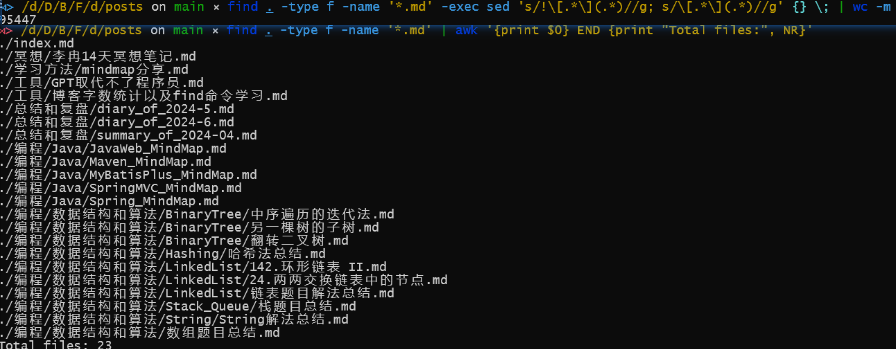
命令解释:
会输出查找到的所有 .md 文件字符的总和,这类排除了.md 文件里 [Link]() 和 ![Img]() 的符号及其里面的内容
find . -type f -name '*.md': 从当前目录开始,递归查找所有扩展名为.md的文件。-exec sed 's/!\[.*\](.*)//g; s/\[\([^]]*\)\](\([^)]*\))//g' {} \;: 对每个找到的文件执行sed命令,该命令会在内存中修改文件内容。这里没有使用-i选项,所以不会修改实际的文件。- 第一个
sed表达式s/!\[.*\](.*)//g删除 Markdown 格式的图片链接, - 第二个表达式
s/\[.*\](.*)//g删除 Markdown 格式的超链接。
- 第一个
| wc -m: 将sed的输出(所有修改后的文件内容)传递到wc -m,它会统计并输出这些内容的总字符数。
题外话:
前面 sed -i 把我坑了,还好用了 git 管理,可以 rollback
然后反复问 gpt 也花了时间,真的问了很多,还是因为自己基础不足。期间 gpt 头昏了还理解错为统计文件大小,而不是字符数量
但怎么说呢 gpt 用来学习命令、写命令还是很好用的。但还是自己有点基础比较好,可以快速理解和验证 gpt 的回答,避免 hallucination